

Engine is an async coding agent that completes software engineering tasks end-to-end – ticket to PR. This means we need to robustly handle a long-running agent loop during which Engine will independently navigate a codebase, run terminal commands, and write code, with little to no user input.
Engine has always used LLMs from several major model labs and our users frequently switch between models. There’s no doubt that some models are more suited to certain tasks or codebases which our users learn mostly through trial and error. This likely extends to model suitability for parts of the same coding task. However, since LLM behaviour is difficult to interpret or predict at a granular level it’s probably impossible to pre-emptively determine which message or tool call should be routed to which model.
Alloyed Agents
An alloyed agent runs on more than one LLM in a single agentic loop with shared context. Credit to XBOW for earlier work on this elegantly simple idea for pentesting, and for giving it a great name.
Last month we quietly shipped LLM ‘alloys’ in beta to learn how they perform on users’ real coding tasks.
Our Implementation
Since Engine has always been model agnostic, our users could already select models from OpenAI, Anthropic, and Google to power Engine’s code agent on a task-by-task basis. As a result, we were able to quickly offer a naïve implementation of model alloys to combine more than one model into a single task run.
Our first alloys combined exactly two models in a single task run by switching between them with each request sent. A simple deterministic solution like this made sense given the challenges observing, interpreting, and predicting LLM behaviour but there are clearly ways to be more sophisticated.
The Test
During two weeks in August, we randomly set the default model for a cohort of new Engine users.
From this user group we selected a random sample of ~500 tasks split between GPT-5, Claude Sonnet 4 and a Sonnet 4 GPT-5 alloy.
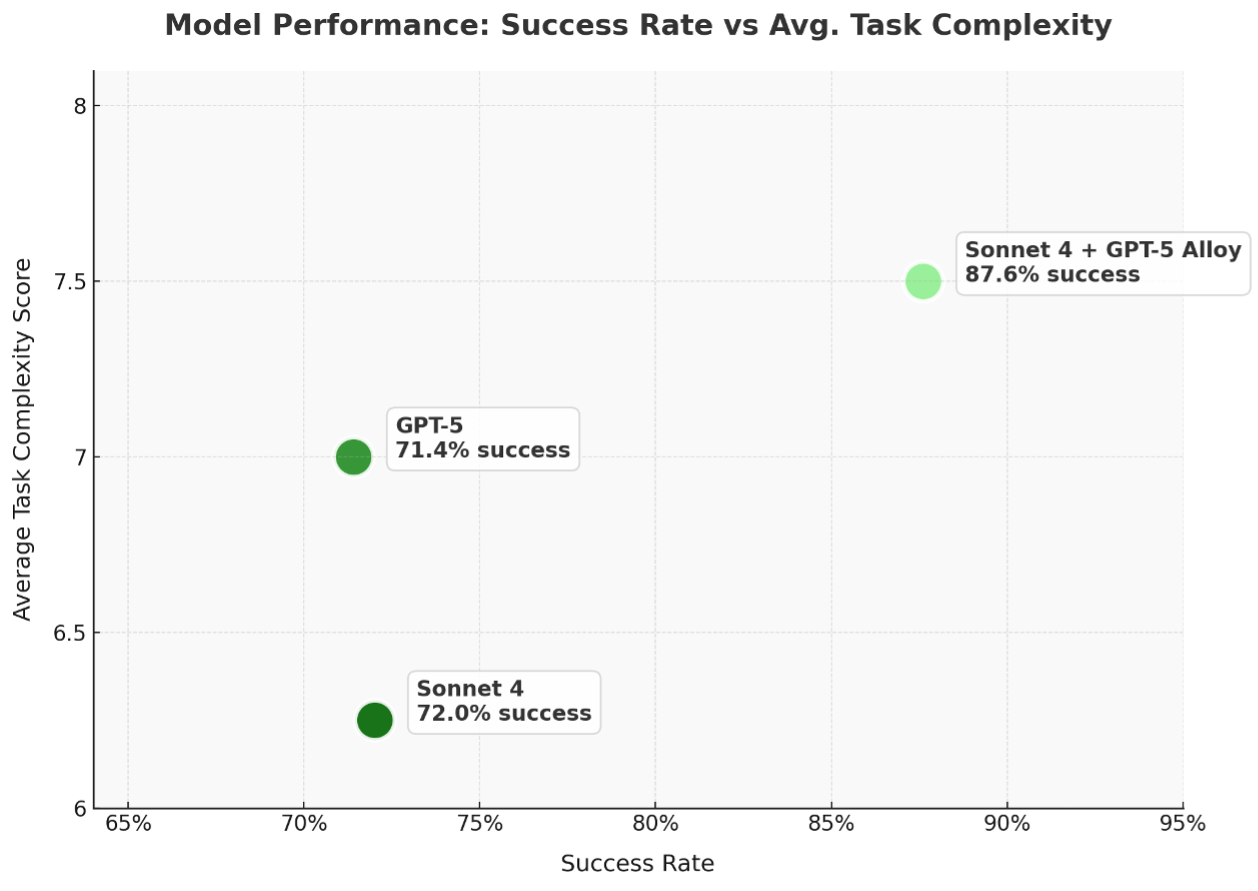
We had GPT-5 loosely classify task difficulty according to the task title and, as we suspected, there was some variance in task difficulty. We speculate this is due to Sonnet 4 being widely regarded as the ‘default’ model for code, with harder tasks being given to GPT-5 or the alloy to try if others fail.
Success rates were measured as the percentage of Engine PR’s that were merged vs total resolved PRs (merged or closed).
The Results
Despite having narrowly harder tasks than the other models, the Sonnet 4 GPT-5 alloy outperformed both GPT-5 and Sonnet 4 individually by over 15 percentage points.

As a bonus, task error rates dropped since the agent was able to continue working even if there were service outages on one of the models. This came in handy during recent intermittent Anthropic API outages.
Interestingly, GPT-5 and Sonnet 4 both had very similar success rates despite GPT-5 API inference costs being approximately half those of Sonnet 4.
These results point to a promising future where a vibrant ecosystem of coding agents exists independently from frontier model labs.
Engine is doubling down on model alloys as well as research across the AI software engineering stack. Sign up to try out alloys and stay on the cutting edge of code agent research as we ship.




